Code
import os
import sys
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executablepyspark for data preprocessingThe data is a parquet file which contains a dataframe with 8 columns:
xid: unique user idaction: type of action. ‘C’ is a click, ‘O’ or ‘VSL’ is a web-displaydate: date of the actionwebsite_id: unique id of the websiteurl: url of the webpagecategory_id: id of the displayzipcode: postal zipcode of the userdevice: type of device used by the userUsing pyspark.sql we want to do the following things:
Then, we want to construct a classifier to predict the click on the category 1204. Here is an agenda for this:
import os
import sys
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executablefrom pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName("Spark Webdata")
.getOrCreate()
)25/05/12 10:25:16 WARN Utils: Your hostname, boucheron-Precision-5480 resolves to a loopback address: 127.0.1.1; using 172.23.32.10 instead (on interface eth0)
25/05/12 10:25:16 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/05/12 10:25:16 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableimport requests, zipfile, io
from pathlib import Path
path = Path('webdata.parquet')
if not path.exists():
url = "https://s-v-b.github.io/IFEBY310/data/webdata.parquet.zip"
r = requests.get(url)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='./')input_path = './'
input_file = os.path.join(input_path, 'webdata.parquet')
df = spark.read.parquet(input_file)We can also give a try to pyarrow.parquet module to load the Parquet file in an Arrow table.
import pyarrow as pa
import comet as co
import pyarrow.parquet as pq
dfa = pq.read_table(input_file)dfa.num_columns8:::
Let us go back to the spark data frame
df.printSchema()root
|-- xid: string (nullable = true)
|-- action: string (nullable = true)
|-- date: timestamp (nullable = true)
|-- website_id: string (nullable = true)
|-- url: string (nullable = true)
|-- category_id: float (nullable = true)
|-- zipcode: string (nullable = true)
|-- device: string (nullable = true)
df.rdd.getNumPartitions()12Explain the partition size.
df.rdd.toDebugString()b'(12) MapPartitionsRDD[7] at javaToPython at NativeMethodAccessorImpl.java:0 []\n | MapPartitionsRDD[6] at javaToPython at NativeMethodAccessorImpl.java:0 []\n | SQLExecutionRDD[5] at javaToPython at NativeMethodAccessorImpl.java:0 []\n | MapPartitionsRDD[4] at javaToPython at NativeMethodAccessorImpl.java:0 []\n | MapPartitionsRDD[3] at javaToPython at NativeMethodAccessorImpl.java:0 []\n | FileScanRDD[2] at javaToPython at NativeMethodAccessorImpl.java:0 []'First we need to import some things:
Window classfrom pyspark.sql import Window
import pyspark.sql.functions as func
from pyspark.sql.types import *
from pyspark.sql.functions import col, lit(
df.select('xid')
.distinct()
.count()
)[Stage 1:=============================> (6 + 6) / 12] 473761def foo(x): yield len(set(x))( df.rdd
.map(lambda x : x.xid)
.mapPartitions(foo)
.collect()
)[Stage 7:=============================> (6 + 6) / 12][Stage 7:======================================> (8 + 4) / 12] [78120, 78636, 79090, 79754, 79296, 78865, 0, 0, 0, 0, 0, 0]This might pump up some computational resources
(
df.select('xid')
.distinct()
.explain()
)== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[xid#0], functions=[])
+- Exchange hashpartitioning(xid#0, 200), ENSURE_REQUIREMENTS, [plan_id=108]
+- HashAggregate(keys=[xid#0], functions=[])
+- FileScan parquet [xid#0] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/home/boucheron/Documents/IFEBY310/core/notebooks/webdata.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<xid:string>
The distinct values of xid seem to be evenly spread among the six files making the parquet directory. Note that the last six partitions look empty.
xid_partition = Window.partitionBy('xid')
n_events = func.count(col('action')).over(xid_partition)
df = df.withColumn('n_events', n_events)
df.head(n=2)[Row(xid='0006cea7-1679-4264-bdef-0cd089749ede', action='O', date=datetime.datetime(2016, 12, 26, 13, 41, 8), website_id='51', url='https://www.footlegende.fr/mercato-psg-coutinho-10166', category_id=1002.0, zipcode='34290', device='TAB', n_events=1),
Row(xid='000893c8-a14b-4f33-858f-210440f37def', action='O', date=datetime.datetime(2016, 12, 23, 16, 18, 37), website_id='56', url='http://blague.dumatin.fr/', category_id=1002.0, zipcode=None, device='DSK', n_events=1)](
df
.groupBy('xid')
.agg(func.count('action'))
.head(5)
)[Row(xid='001c4a21-52c6-4890-b6ce-2b9d4ba06a56', count(action)=1),
Row(xid='0024344b-7ee2-4fcd-a0b4-bec26d8c8b0e', count(action)=4),
Row(xid='004564e3-87c1-4e16-ad2c-0e96afc3d617', count(action)=1),
Row(xid='006d807f-91c3-415a-bb5e-6b9f7e6517a1', count(action)=1),
Row(xid='006e0463-b24c-4996-84ab-d6d0d65a52aa', count(action)=1)]max_date = (
func
.max(col('date'))
.over(xid_partition)
)
n_days_since_last_event = func.datediff(func.current_date(), max_date)
df = df.withColumn('n_days_since_last_event',
n_days_since_last_event)
df.head(n=2)[Row(xid='0006cea7-1679-4264-bdef-0cd089749ede', action='O', date=datetime.datetime(2016, 12, 26, 13, 41, 8), website_id='51', url='https://www.footlegende.fr/mercato-psg-coutinho-10166', category_id=1002.0, zipcode='34290', device='TAB', n_events=1, n_days_since_last_event=3059),
Row(xid='000893c8-a14b-4f33-858f-210440f37def', action='O', date=datetime.datetime(2016, 12, 23, 16, 18, 37), website_id='56', url='http://blague.dumatin.fr/', category_id=1002.0, zipcode=None, device='DSK', n_events=1, n_days_since_last_event=3062)]df.printSchema()root
|-- xid: string (nullable = true)
|-- action: string (nullable = true)
|-- date: timestamp (nullable = true)
|-- website_id: string (nullable = true)
|-- url: string (nullable = true)
|-- category_id: float (nullable = true)
|-- zipcode: string (nullable = true)
|-- device: string (nullable = true)
|-- n_events: long (nullable = false)
|-- n_days_since_last_event: integer (nullable = true)
Does this partitionBy triggers shuffling?
xid_device_partition = xid_partition.partitionBy('device')
n_events_per_device = func.count(col('action')).over(xid_device_partition)
df = df.withColumn('n_events_per_device', n_events_per_device)
df.head(n=2)[Stage 19:==> (1 + 20) / 22] [Row(xid='000893c8-a14b-4f33-858f-210440f37def', action='O', date=datetime.datetime(2016, 12, 23, 16, 18, 37), website_id='56', url='http://blague.dumatin.fr/', category_id=1002.0, zipcode=None, device='DSK', n_events=1, n_days_since_last_event=3062, n_events_per_device=1021837),
Row(xid='0008c5d2-c263-4b55-ae7d-82c4bf566cc4', action='O', date=datetime.datetime(2017, 1, 16, 4, 26, 21), website_id='74', url='http://www.realite-virtuelle.com/meilleure-videos-360-vr', category_id=1002.0, zipcode=None, device='DSK', n_events=1, n_days_since_last_event=3038, n_events_per_device=1021837)]# xid_partition = Window.partitionBy('xid')
rank_device = (
func
.dense_rank()
.over(xid_partition.orderBy('device'))
)
n_unique_device = (
func
.last(rank_device)
.over(xid_partition)
)
df = df.withColumn('n_device', n_unique_device)
df.head(n=2)[Stage 28:======================================> (2 + 1) / 3] [Row(xid='0006cea7-1679-4264-bdef-0cd089749ede', action='O', date=datetime.datetime(2016, 12, 26, 13, 41, 8), website_id='51', url='https://www.footlegende.fr/mercato-psg-coutinho-10166', category_id=1002.0, zipcode='34290', device='TAB', n_events=1, n_days_since_last_event=3059, n_events_per_device=132013, n_device=1),
Row(xid='000893c8-a14b-4f33-858f-210440f37def', action='O', date=datetime.datetime(2016, 12, 23, 16, 18, 37), website_id='56', url='http://blague.dumatin.fr/', category_id=1002.0, zipcode=None, device='DSK', n_events=1, n_days_since_last_event=3062, n_events_per_device=1021837, n_device=1)]df\
.where(col('n_device') > 1)\
.select('xid', 'device', 'n_events', 'n_device', 'n_events_per_device')\
.head(n=8)[Stage 38:=============================> (1 + 1) / 2] [Row(xid='4c1dc79d-a140-4da9-ae28-540b4503c3b8', device='DSK', n_events=6, n_device=2, n_events_per_device=1021837),
Row(xid='4c1dc79d-a140-4da9-ae28-540b4503c3b8', device='DSK', n_events=6, n_device=2, n_events_per_device=1021837),
Row(xid='4c1dc79d-a140-4da9-ae28-540b4503c3b8', device='DSK', n_events=6, n_device=2, n_events_per_device=1021837),
Row(xid='4c1dc79d-a140-4da9-ae28-540b4503c3b8', device='DSK', n_events=6, n_device=2, n_events_per_device=1021837),
Row(xid='4c1dc79d-a140-4da9-ae28-540b4503c3b8', device='DSK', n_events=6, n_device=2, n_events_per_device=1021837),
Row(xid='4c1dc79d-a140-4da9-ae28-540b4503c3b8', device='MOB', n_events=6, n_device=2, n_events_per_device=1564),
Row(xid='78156cdf-7229-46eb-bb6b-92d384f9a6fa', device='DSK', n_events=6, n_device=2, n_events_per_device=1021837),
Row(xid='78156cdf-7229-46eb-bb6b-92d384f9a6fa', device='DSK', n_events=6, n_device=2, n_events_per_device=1021837)]df\
.where(col('n_device') > 1)\
.select('xid', 'device', 'n_events', 'n_device', 'n_events_per_device')\
.count()3153We construct a ETL (Extract Transform Load) process on this data using the pyspark.sql API.
Here extraction is just about reading the data
df = spark.read.parquet(input_file)
df.head(n=3)[Row(xid='001ff9b6-5383-4221-812d-58c2c3f234cc', action='O', date=datetime.datetime(2017, 1, 25, 7, 2, 18), website_id='3', url='http://www.8chances.com/grille', category_id=1002.0, zipcode='11370', device='SMP'),
Row(xid='0056ab7a-3cba-4ed5-a495-3d4abf79ab66', action='O', date=datetime.datetime(2016, 12, 28, 9, 47, 8), website_id='54', url='http://www.salaire-brut-en-net.fr/differences-brut-net/', category_id=1002.0, zipcode='86000', device='DSK'),
Row(xid='005ae4ab-363a-41a0-b8f9-faee47d622a4', action='O', date=datetime.datetime(2017, 1, 27, 22, 21, 6), website_id='74', url='http://www.realite-virtuelle.com/top-applications-horreur-vr-halloween', category_id=1002.0, zipcode='49700', device='DSK')]At this step we compute a lot of extra things from the data. The aim is to build features that describe users.
def n_events_transformer(df):
xid_partition = Window.partitionBy('xid')
n_events = func.count(col('action')).over(xid_partition)
df = df.withColumn('n_events', n_events)
return dfdef n_events_per_action_transformer(df):
xid_action_partition = Window.partitionBy('xid', 'action')
n_events_per_action = func.count(col('action')).over(xid_action_partition)
df = df.withColumn('n_events_per_action', n_events_per_action)
return dfdef hour_transformer(df):
hour = func.hour(col('date'))
df = df.withColumn('hour', hour)
return df
def weekday_transformer(df):
weekday = func.date_format(col('date'), 'EEEE')
df = df.withColumn('weekday', weekday)
return df
def n_events_per_hour_transformer(df):
xid_hour_partition = Window.partitionBy('xid', 'hour')
n_events_per_hour = func.count(col('action')).over(xid_hour_partition)
df = df.withColumn('n_events_per_hour', n_events_per_hour)
return df
def n_events_per_weekday_transformer(df):
xid_weekday_partition = Window.partitionBy('xid', 'weekday')
n_events_per_weekday = func.count(col('action')).over(xid_weekday_partition)
df = df.withColumn('n_events_per_weekday', n_events_per_weekday)
return df
def n_days_since_last_event_transformer(df):
xid_partition = Window.partitionBy('xid')
max_date = func.max(col('date')).over(xid_partition)
n_days_since_last_event = func.datediff(func.current_date(), max_date)
df = df.withColumn('n_days_since_last_event',
n_days_since_last_event + lit(0.1))
return df
def n_days_since_last_action_transformer(df):
xid_partition_action = Window.partitionBy('xid', 'action')
max_date = func.max(col('date')).over(xid_partition_action)
n_days_since_last_action = func.datediff(func.current_date(),
max_date)
df = df.withColumn('n_days_since_last_action',
n_days_since_last_action + lit(0.1))
return df
def n_unique_day_transformer(df):
xid_partition = Window.partitionBy('xid')
dayofyear = func.dayofyear(col('date'))
rank_day = func.dense_rank().over(xid_partition.orderBy(dayofyear))
n_unique_day = func.last(rank_day).over(xid_partition)
df = df.withColumn('n_unique_day', n_unique_day)
return df
def n_unique_hour_transformer(df):
xid_partition = Window.partitionBy('xid')
rank_hour = func.dense_rank().over(xid_partition.orderBy('hour'))
n_unique_hour = func.last(rank_hour).over(xid_partition)
df = df.withColumn('n_unique_hour', n_unique_hour)
return df
def n_events_per_device_transformer(df):
xid_device_partition = Window.partitionBy('xid', 'device')
n_events_per_device = func.count(func.col('device')) \
.over(xid_device_partition)
df = df.withColumn('n_events_per_device', n_events_per_device)
return df
def n_unique_device_transformer(df):
xid_partition = Window.partitionBy('xid')
rank_device = func.dense_rank().over(xid_partition.orderBy('device'))
n_unique_device = func.last(rank_device).over(xid_partition)
df = df.withColumn('n_device', n_unique_device)
return df
def n_actions_per_category_id_transformer(df):
xid_category_id_partition = Window.partitionBy('xid', 'category_id',
'action')
n_actions_per_category_id = func.count(func.col('action')) \
.over(xid_category_id_partition)
df = df.withColumn('n_actions_per_category_id', n_actions_per_category_id)
return df
def n_unique_category_id_transformer(df):
xid_partition = Window.partitionBy('xid')
rank_category_id = func.dense_rank().over(xid_partition\
.orderBy('category_id'))
n_unique_category_id = func.last(rank_category_id).over(xid_partition)
df = df.withColumn('n_unique_category_id', n_unique_category_id)
return df
def n_events_per_category_id_transformer(df):
xid_category_id_partition = Window.partitionBy('xid', 'category_id')
n_events_per_category_id = func.count(func.col('action')) \
.over(xid_category_id_partition)
df = df.withColumn('n_events_per_category_id', n_events_per_category_id)
return df
def n_events_per_website_id_transformer(df):
xid_website_id_partition = Window.partitionBy('xid', 'website_id')
n_events_per_website_id = func.count(col('action'))\
.over(xid_website_id_partition)
df = df.withColumn('n_events_per_website_id', n_events_per_website_id)
return dftransformers = [
hour_transformer,
weekday_transformer,
n_events_per_hour_transformer,
n_events_per_weekday_transformer,
n_days_since_last_event_transformer,
n_days_since_last_action_transformer,
n_unique_day_transformer,
n_unique_hour_transformer,
n_events_per_device_transformer,
n_unique_device_transformer,
n_actions_per_category_id_transformer,
n_events_per_category_id_transformer,
n_events_per_website_id_transformer,
]N = 10000sample_df = df.sample(withReplacement=False, fraction=.05)sample_df.count()59192for transformer in transformers:
df = transformer(df)
df.head(n=1)[Stage 56:> (0 + 1) / 1] [Row(xid='0006cea7-1679-4264-bdef-0cd089749ede', action='O', date=datetime.datetime(2016, 12, 26, 13, 41, 8), website_id='51', url='https://www.footlegende.fr/mercato-psg-coutinho-10166', category_id=1002.0, zipcode='34290', device='TAB', hour=13, weekday='Monday', n_events_per_hour=1, n_events_per_weekday=1, n_days_since_last_event=3059.1, n_days_since_last_action=3059.1, n_unique_day=1, n_unique_hour=1, n_events_per_device=1, n_device=1, n_actions_per_category_id=1, n_events_per_category_id=1, n_events_per_website_id=1)]for transformer in transformers:
sample_df = transformer(sample_df)
sample_df.head(n=1)[Row(xid='0004d0b7-a7fd-44ca-accc-422b62de4436', action='O', date=datetime.datetime(2017, 1, 19, 8, 9, 24), website_id='3', url='http://www.8chances.com/', category_id=1002.0, zipcode='78480', device='DSK', hour=8, weekday='Thursday', n_events_per_hour=1, n_events_per_weekday=1, n_days_since_last_event=3035.1, n_days_since_last_action=3035.1, n_unique_day=1, n_unique_hour=1, n_events_per_device=1, n_device=1, n_actions_per_category_id=1, n_events_per_category_id=1, n_events_per_website_id=1)]df = sample_dfsorted(df.columns)['action',
'category_id',
'date',
'device',
'hour',
'n_actions_per_category_id',
'n_days_since_last_action',
'n_days_since_last_event',
'n_device',
'n_events_per_category_id',
'n_events_per_device',
'n_events_per_hour',
'n_events_per_website_id',
'n_events_per_weekday',
'n_unique_day',
'n_unique_hour',
'url',
'website_id',
'weekday',
'xid',
'zipcode']df.explain()== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Window [count(action#298) windowspecdefinition(xid#297, website_id#300, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_website_id#841L], [xid#297, website_id#300]
+- Sort [xid#297 ASC NULLS FIRST, website_id#300 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_events_per_device#747L, n_device#768, n_actions_per_category_id#798L, n_events_per_category_id#819L]
+- Window [count(action#298) windowspecdefinition(xid#297, category_id#302, action#298, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_actions_per_category_id#798L], [xid#297, knownfloatingpointnormalized(normalizenanandzero(category_id#302)), action#298]
+- Sort [xid#297 ASC NULLS FIRST, knownfloatingpointnormalized(normalizenanandzero(category_id#302)) ASC NULLS FIRST, action#298 ASC NULLS FIRST], false, 0
+- Window [count(action#298) windowspecdefinition(xid#297, category_id#302, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_category_id#819L], [xid#297, knownfloatingpointnormalized(normalizenanandzero(category_id#302))]
+- Sort [xid#297 ASC NULLS FIRST, knownfloatingpointnormalized(normalizenanandzero(category_id#302)) ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_events_per_device#747L, n_device#768]
+- Window [count(device#304) windowspecdefinition(xid#297, device#304, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_device#747L], [xid#297, device#304]
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_device#768]
+- Window [last(_w0#775, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_device#768], [xid#297]
+- Window [dense_rank(device#304) windowspecdefinition(xid#297, device#304 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#775], [xid#297], [device#304 ASC NULLS FIRST]
+- Sort [xid#297 ASC NULLS FIRST, device#304 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719]
+- Window [last(_w0#726, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_unique_hour#719], [xid#297]
+- Window [dense_rank(hour#602) windowspecdefinition(xid#297, hour#602 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#726], [xid#297], [hour#602 ASC NULLS FIRST]
+- Sort [xid#297 ASC NULLS FIRST, hour#602 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686]
+- Window [last(_w0#693, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_unique_day#686], [xid#297]
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, _w0#693]
+- Window [dense_rank(_w0#694) windowspecdefinition(xid#297, _w0#694 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#693], [xid#297], [_w0#694 ASC NULLS FIRST]
+- Sort [xid#297 ASC NULLS FIRST, _w0#694 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, (cast(datediff(2025-05-12, cast(_we0#668 as date)) as double) + 0.1) AS n_days_since_last_action#667, dayofyear(cast(date#299 as date)) AS _w0#694]
+- Window [max(date#299) windowspecdefinition(xid#297, action#298, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we0#668], [xid#297, action#298]
+- Sort [xid#297 ASC NULLS FIRST, action#298 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, (cast(datediff(2025-05-12, cast(_we0#652 as date)) as double) + 0.1) AS n_days_since_last_event#651]
+- Window [count(action#298) windowspecdefinition(xid#297, weekday#612, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_weekday#637L], [xid#297, weekday#612]
+- Sort [xid#297 ASC NULLS FIRST, weekday#612 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, _we0#652]
+- Window [count(action#298) windowspecdefinition(xid#297, hour#602, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_hour#624L], [xid#297, hour#602]
+- Sort [xid#297 ASC NULLS FIRST, hour#602 ASC NULLS FIRST], false, 0
+- Window [max(date#299) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we0#652], [xid#297]
+- Sort [xid#297 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(xid#297, 200), ENSURE_REQUIREMENTS, [plan_id=2113]
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour(date#299, Some(Europe/Paris)) AS hour#602, date_format(date#299, EEEE, Some(Europe/Paris)) AS weekday#612]
+- Sample 0.0, 0.05, false, -2470152187269908205
+- FileScan parquet [xid#297,action#298,date#299,website_id#300,url#301,category_id#302,zipcode#303,device#304] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/home/boucheron/Documents/IFEBY310/core/notebooks/webdata.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<xid:string,action:string,date:timestamp,website_id:string,url:string,category_id:float,zip...
spark._sc.setCheckpointDir(".")
df.checkpoint()DataFrame[xid: string, action: string, date: timestamp, website_id: string, url: string, category_id: float, zipcode: string, device: string, hour: int, weekday: string, n_events_per_hour: bigint, n_events_per_weekday: bigint, n_days_since_last_event: double, n_days_since_last_action: double, n_unique_day: int, n_unique_hour: int, n_events_per_device: bigint, n_device: int, n_actions_per_category_id: bigint, n_events_per_category_id: bigint, n_events_per_website_id: bigint]df.explain()== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=true
+- == Final Plan ==
Window [count(action#298) windowspecdefinition(xid#297, website_id#300, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_website_id#841L], [xid#297, website_id#300]
+- *(13) Sort [xid#297 ASC NULLS FIRST, website_id#300 ASC NULLS FIRST], false, 0
+- *(13) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_events_per_device#747L, n_device#768, n_actions_per_category_id#798L, n_events_per_category_id#819L]
+- Window [count(action#298) windowspecdefinition(xid#297, category_id#302, action#298, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_actions_per_category_id#798L], [xid#297, knownfloatingpointnormalized(normalizenanandzero(category_id#302)), action#298]
+- *(12) Sort [xid#297 ASC NULLS FIRST, knownfloatingpointnormalized(normalizenanandzero(category_id#302)) ASC NULLS FIRST, action#298 ASC NULLS FIRST], false, 0
+- Window [count(action#298) windowspecdefinition(xid#297, category_id#302, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_category_id#819L], [xid#297, knownfloatingpointnormalized(normalizenanandzero(category_id#302))]
+- *(11) Sort [xid#297 ASC NULLS FIRST, knownfloatingpointnormalized(normalizenanandzero(category_id#302)) ASC NULLS FIRST], false, 0
+- *(11) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_events_per_device#747L, n_device#768]
+- Window [count(device#304) windowspecdefinition(xid#297, device#304, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_device#747L], [xid#297, device#304]
+- *(10) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_device#768]
+- Window [last(_w0#775, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_device#768], [xid#297]
+- Window [dense_rank(device#304) windowspecdefinition(xid#297, device#304 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#775], [xid#297], [device#304 ASC NULLS FIRST]
+- *(9) Sort [xid#297 ASC NULLS FIRST, device#304 ASC NULLS FIRST], false, 0
+- *(9) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719]
+- Window [last(_w0#726, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_unique_hour#719], [xid#297]
+- Window [dense_rank(hour#602) windowspecdefinition(xid#297, hour#602 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#726], [xid#297], [hour#602 ASC NULLS FIRST]
+- *(8) Sort [xid#297 ASC NULLS FIRST, hour#602 ASC NULLS FIRST], false, 0
+- *(8) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686]
+- Window [last(_w0#693, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_unique_day#686], [xid#297]
+- *(7) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, _w0#693]
+- Window [dense_rank(_w0#694) windowspecdefinition(xid#297, _w0#694 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#693], [xid#297], [_w0#694 ASC NULLS FIRST]
+- *(6) Sort [xid#297 ASC NULLS FIRST, _w0#694 ASC NULLS FIRST], false, 0
+- *(6) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, (cast(datediff(2025-05-12, cast(_we0#668 as date)) as double) + 0.1) AS n_days_since_last_action#667, dayofyear(cast(date#299 as date)) AS _w0#694]
+- Window [max(date#299) windowspecdefinition(xid#297, action#298, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we0#668], [xid#297, action#298]
+- *(5) Sort [xid#297 ASC NULLS FIRST, action#298 ASC NULLS FIRST], false, 0
+- *(5) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, (cast(datediff(2025-05-12, cast(_we0#652 as date)) as double) + 0.1) AS n_days_since_last_event#651]
+- Window [count(action#298) windowspecdefinition(xid#297, weekday#612, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_weekday#637L], [xid#297, weekday#612]
+- *(4) Sort [xid#297 ASC NULLS FIRST, weekday#612 ASC NULLS FIRST], false, 0
+- *(4) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, _we0#652]
+- Window [count(action#298) windowspecdefinition(xid#297, hour#602, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_hour#624L], [xid#297, hour#602]
+- *(3) Sort [xid#297 ASC NULLS FIRST, hour#602 ASC NULLS FIRST], false, 0
+- Window [max(date#299) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we0#652], [xid#297]
+- *(2) Sort [xid#297 ASC NULLS FIRST], false, 0
+- AQEShuffleRead coalesced
+- ShuffleQueryStage 0
+- Exchange hashpartitioning(xid#297, 200), ENSURE_REQUIREMENTS, [plan_id=2171]
+- *(1) Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour(date#299, Some(Europe/Paris)) AS hour#602, date_format(date#299, EEEE, Some(Europe/Paris)) AS weekday#612]
+- *(1) Sample 0.0, 0.05, false, -2470152187269908205
+- *(1) ColumnarToRow
+- FileScan parquet [xid#297,action#298,date#299,website_id#300,url#301,category_id#302,zipcode#303,device#304] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/home/boucheron/Documents/IFEBY310/core/notebooks/webdata.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<xid:string,action:string,date:timestamp,website_id:string,url:string,category_id:float,zip...
+- == Initial Plan ==
Window [count(action#298) windowspecdefinition(xid#297, website_id#300, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_website_id#841L], [xid#297, website_id#300]
+- Sort [xid#297 ASC NULLS FIRST, website_id#300 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_events_per_device#747L, n_device#768, n_actions_per_category_id#798L, n_events_per_category_id#819L]
+- Window [count(action#298) windowspecdefinition(xid#297, category_id#302, action#298, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_actions_per_category_id#798L], [xid#297, knownfloatingpointnormalized(normalizenanandzero(category_id#302)), action#298]
+- Sort [xid#297 ASC NULLS FIRST, knownfloatingpointnormalized(normalizenanandzero(category_id#302)) ASC NULLS FIRST, action#298 ASC NULLS FIRST], false, 0
+- Window [count(action#298) windowspecdefinition(xid#297, category_id#302, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_category_id#819L], [xid#297, knownfloatingpointnormalized(normalizenanandzero(category_id#302))]
+- Sort [xid#297 ASC NULLS FIRST, knownfloatingpointnormalized(normalizenanandzero(category_id#302)) ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_events_per_device#747L, n_device#768]
+- Window [count(device#304) windowspecdefinition(xid#297, device#304, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_device#747L], [xid#297, device#304]
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719, n_device#768]
+- Window [last(_w0#775, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_device#768], [xid#297]
+- Window [dense_rank(device#304) windowspecdefinition(xid#297, device#304 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#775], [xid#297], [device#304 ASC NULLS FIRST]
+- Sort [xid#297 ASC NULLS FIRST, device#304 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686, n_unique_hour#719]
+- Window [last(_w0#726, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_unique_hour#719], [xid#297]
+- Window [dense_rank(hour#602) windowspecdefinition(xid#297, hour#602 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#726], [xid#297], [hour#602 ASC NULLS FIRST]
+- Sort [xid#297 ASC NULLS FIRST, hour#602 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, n_unique_day#686]
+- Window [last(_w0#693, false) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_unique_day#686], [xid#297]
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, n_days_since_last_action#667, _w0#693]
+- Window [dense_rank(_w0#694) windowspecdefinition(xid#297, _w0#694 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#693], [xid#297], [_w0#694 ASC NULLS FIRST]
+- Sort [xid#297 ASC NULLS FIRST, _w0#694 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, n_days_since_last_event#651, (cast(datediff(2025-05-12, cast(_we0#668 as date)) as double) + 0.1) AS n_days_since_last_action#667, dayofyear(cast(date#299 as date)) AS _w0#694]
+- Window [max(date#299) windowspecdefinition(xid#297, action#298, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we0#668], [xid#297, action#298]
+- Sort [xid#297 ASC NULLS FIRST, action#298 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, n_events_per_weekday#637L, (cast(datediff(2025-05-12, cast(_we0#652 as date)) as double) + 0.1) AS n_days_since_last_event#651]
+- Window [count(action#298) windowspecdefinition(xid#297, weekday#612, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_weekday#637L], [xid#297, weekday#612]
+- Sort [xid#297 ASC NULLS FIRST, weekday#612 ASC NULLS FIRST], false, 0
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour#602, weekday#612, n_events_per_hour#624L, _we0#652]
+- Window [count(action#298) windowspecdefinition(xid#297, hour#602, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS n_events_per_hour#624L], [xid#297, hour#602]
+- Sort [xid#297 ASC NULLS FIRST, hour#602 ASC NULLS FIRST], false, 0
+- Window [max(date#299) windowspecdefinition(xid#297, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we0#652], [xid#297]
+- Sort [xid#297 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(xid#297, 200), ENSURE_REQUIREMENTS, [plan_id=2113]
+- Project [xid#297, action#298, date#299, website_id#300, url#301, category_id#302, zipcode#303, device#304, hour(date#299, Some(Europe/Paris)) AS hour#602, date_format(date#299, EEEE, Some(Europe/Paris)) AS weekday#612]
+- Sample 0.0, 0.05, false, -2470152187269908205
+- FileScan parquet [xid#297,action#298,date#299,website_id#300,url#301,category_id#302,zipcode#303,device#304] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/home/boucheron/Documents/IFEBY310/core/notebooks/webdata.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<xid:string,action:string,date:timestamp,website_id:string,url:string,category_id:float,zip...
Here, we use all the previous computations (saved in the columns of the dataframe) to compute aggregated informations about each user.
This should be DRYED
def n_events_per_hour_loader(df):
csr = df\
.select('xid', 'hour', 'n_events_per_hour')\
.withColumnRenamed('n_events_per_hour', 'value')\
.distinct()
# action
feature_name = func.concat(lit('n_events_per_hour#'), col('hour'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('hour')
return csr
def n_events_per_website_id_loader(df):
csr = df.select('xid', 'website_id', 'n_events_per_website_id')\
.withColumnRenamed('n_events_per_hour', 'value')\
.distinct()
feature_name = func.concat(lit('n_events_per_website_id#'),
col('website_id'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('website_id')
return csr
def n_events_per_hour_loader(df):
csr = df\
.select('xid', 'hour', 'n_events_per_hour')\
.withColumnRenamed('n_events_per_hour', 'value')\
.distinct()
feature_name = func.concat(lit('n_events_per_hour#'), col('hour'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('hour')
return csr
def n_events_per_weekday_loader(df):
csr = df\
.select('xid', 'weekday', 'n_events_per_weekday')\
.withColumnRenamed('n_events_per_weekday', 'value')\
.distinct()
feature_name = func.concat(lit('n_events_per_weekday#'), col('weekday'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('weekday')
return csr
def n_days_since_last_event_loader(df):
csr = df.select('xid', 'n_days_since_last_event')\
.withColumnRenamed('n_days_since_last_event', 'value')\
.distinct()
feature_name = lit('n_days_since_last_event')
csr = csr\
.withColumn('feature_name', feature_name)
return csr
def n_days_since_last_action_loader(df):
csr = df.select('xid', 'action', 'n_days_since_last_action')\
.withColumnRenamed('n_days_since_last_action', 'value')\
.distinct()
feature_name = func.concat(lit('n_days_since_last_action#'), col('action'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('action')
return csr
def n_unique_day_loader(df):
csr = df.select('xid', 'n_unique_day')\
.withColumnRenamed('n_unique_day', 'value')\
.distinct()
feature_name = lit('n_unique_day')
csr = csr\
.withColumn('feature_name', feature_name)
return csr
def n_unique_hour_loader(df):
csr = df.select('xid', 'n_unique_hour')\
.withColumnRenamed('n_unique_hour', 'value')\
.distinct()
feature_name = lit('n_unique_hour')
csr = csr\
.withColumn('feature_name', feature_name)
return csr
def n_events_per_device_loader(df):
csr = df\
.select('xid', 'device', 'n_events_per_device')\
.withColumnRenamed('n_events_per_device', 'value')\
.distinct()
feature_name = func.concat(lit('n_events_per_device#'), col('device'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('device')
return csr
def n_unique_device_loader(df):
csr = df.select('xid', 'n_device')\
.withColumnRenamed('n_device', 'value')\
.distinct()
feature_name = lit('n_device')
csr = csr\
.withColumn('feature_name', feature_name)
return csr
def n_events_per_category_id_loader(df):
csr = df.select('xid', 'category_id', 'n_events_per_category_id')\
.withColumnRenamed('n_events_per_category_id', 'value')\
.distinct()
feature_name = func.concat(lit('n_events_per_category_id#'),
col('category_id'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('category_id')
return csr
def n_actions_per_category_id_loader(df):
csr = df.select('xid', 'category_id', 'action', 'n_actions_per_category_id')\
.withColumnRenamed('n_actions_per_category_id', 'value')\
.distinct()
feature_name = func.concat(lit('n_actions_per_category_id#'),
col('action'), lit('#'),
col('category_id'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('category_id')\
.drop('action')
return csr
def n_events_per_website_id_loader(df):
csr = df.select('xid', 'website_id', 'n_events_per_website_id')\
.withColumnRenamed('n_events_per_website_id', 'value')\
.distinct()
feature_name = func.concat(lit('n_events_per_website_id#'),
col('website_id'))
csr = csr\
.withColumn('feature_name', feature_name)\
.drop('website_id')
return csrfrom functools import reduceloaders = [
n_events_per_hour_loader,
n_events_per_website_id_loader,
n_events_per_hour_loader,
n_events_per_weekday_loader,
n_days_since_last_event_loader,
n_days_since_last_action_loader,
n_unique_day_loader,
n_unique_hour_loader,
n_events_per_device_loader,
n_unique_device_loader,
n_events_per_category_id_loader,
n_actions_per_category_id_loader,
n_events_per_website_id_loader,
]def union(df, other):
return df.union(other)This method performs a SQL-style set union of the rows from both DataFrame objects, with no automatic deduplication of elements.
Use the distinct() method to perform deduplication of rows.
The method resolves columns by position (not by name), following the standard behavior in SQL.
spam = [loader(df) for loader in loaders]spam[0].printSchema()root
|-- xid: string (nullable = true)
|-- value: long (nullable = false)
|-- feature_name: string (nullable = true)
all(spam[0].columns == it.columns for it in spam[1:])Truelen(spam)13csr = reduce(
lambda df1, df2: df1.union(df2),
spam
)
csr.head(n=3)[Row(xid='0004d0b7-a7fd-44ca-accc-422b62de4436', value=1.0, feature_name='n_events_per_hour#8'),
Row(xid='00077fd6-ea8c-4128-9c84-74075ad226a0', value=1.0, feature_name='n_events_per_hour#17'),
Row(xid='000fcd14-ce41-461d-a2aa-cb407630a03a', value=8.0, feature_name='n_events_per_hour#16')]csr.columns['xid', 'value', 'feature_name']csr.show(5)+--------------------+-----+--------------------+
| xid|value| feature_name|
+--------------------+-----+--------------------+
|0004d0b7-a7fd-44c...| 1.0| n_events_per_hour#8|
|00077fd6-ea8c-412...| 1.0|n_events_per_hour#17|
|000fcd14-ce41-461...| 8.0|n_events_per_hour#16|
|00109f2e-f0ff-423...| 1.0|n_events_per_hour#19|
|00142eb6-ade4-4f5...| 1.0| n_events_per_hour#9|
+--------------------+-----+--------------------+
only showing top 5 rows
csr.rdd.getNumPartitions()17# Replace features names and xid by a unique number
feature_name_partition = Window().orderBy('feature_name')
xid_partition = Window().orderBy('xid')
col_idx = func.dense_rank().over(feature_name_partition)
row_idx = func.dense_rank().over(xid_partition)csr = csr.withColumn('col', col_idx)\
.withColumn('row', row_idx)
csr = csr.na.drop('any')
csr.head(n=5)25/05/12 10:25:38 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:38 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:38 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:38 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:38 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:39 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:40 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:40 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:40 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:40 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.[Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=1.0, feature_name='n_actions_per_category_id#O#1002.0', col=3, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=3022.1, feature_name='n_days_since_last_action#O', col=6, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=3022.1, feature_name='n_days_since_last_event', col=7, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=1.0, feature_name='n_device', col=8, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=1.0, feature_name='n_events_per_category_id#1002.0', col=9, row=1)]# Let's save the result of our hard work into a new parquet file
output_path = './'
output_file = os.path.join(output_path, 'csr.parquet')
csr.write.parquet(output_file, mode='overwrite')25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:41 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:42 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:43 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:43 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:43 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:43 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
[Stage 223:> (0 + 1) / 1] csr_path = './'
csr_file = os.path.join(csr_path, 'csr.parquet')
df = spark.read.parquet(csr_file)
df.head(n=5)[Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=1.0, feature_name='n_actions_per_category_id#O#1002.0', col=3, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=3022.1, feature_name='n_days_since_last_action#O', col=6, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=3022.1, feature_name='n_days_since_last_event', col=7, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=1.0, feature_name='n_device', col=8, row=1),
Row(xid='00044fed-c55e-4750-8dbf-7a3aa90f772e', value=1.0, feature_name='n_events_per_category_id#1002.0', col=9, row=1)]df.count()518673# What are the features related to campaign_id 1204 ?
features_names = \
df.select('feature_name')\
.distinct()\
.toPandas()['feature_name']features_names0 n_events_per_website_id#25
1 n_events_per_weekday#Sunday
2 n_events_per_website_id#42
3 n_events_per_hour#0
4 n_events_per_hour#10
...
93 n_events_per_hour#19
94 n_events_per_website_id#29
95 n_events_per_website_id#60
96 n_events_per_weekday#Monday
97 n_events_per_website_id#32
Name: feature_name, Length: 98, dtype: object[feature_name for feature_name in features_names if '1204' in feature_name]['n_events_per_category_id#1204.0',
'n_actions_per_category_id#C#1204.0',
'n_actions_per_category_id#O#1204.0']# Look for the xid that have at least one exposure to campaign 1204
keep = func.when(
(col('feature_name') == 'n_actions_per_category_id#C#1204.0') |
(col('feature_name') == 'n_actions_per_category_id#O#1204.0'),
1).otherwise(0)
df = df.withColumn('keep', keep)
df.where(col('keep') > 0).count()11022# Sum of the keeps :)
xid_partition = Window.partitionBy('xid')
sum_keep = func.sum(col('keep')).over(xid_partition)
df = df.withColumn('sum_keep', sum_keep)# Let's keep the xid exposed to 1204
df = df.where(col('sum_keep') > 0)df.count()158030df.select('xid').distinct().count()11009row_partition = Window().orderBy('row')
col_partition = Window().orderBy('col')
row_new = func.dense_rank().over(row_partition)
col_new = func.dense_rank().over(col_partition)
df = df.withColumn('row_new', row_new)
df = df.withColumn('col_new', col_new)
csr_data = df.select('row_new', 'col_new', 'value').toPandas()25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:45 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.csr_data.head()| row_new | col_new | value | |
|---|---|---|---|
| 0 | 219 | 1 | 1.0 |
| 1 | 1617 | 1 | 1.0 |
| 2 | 5965 | 1 | 1.0 |
| 3 | 8650 | 1 | 1.0 |
| 4 | 9705 | 1 | 1.0 |
features_names = df.select('feature_name', 'col_new').distinct()
features_names.where(col('feature_name') == 'n_actions_per_category_id#C#1204.0').head()25/05/12 10:25:46 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:46 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:46 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:46 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:46 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.Row(feature_name='n_actions_per_category_id#C#1204.0', col_new=2)features_names.where(col('feature_name') == 'n_actions_per_category_id#O#1204.0').head()25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.Row(feature_name='n_actions_per_category_id#O#1204.0', col_new=4)from scipy.sparse import csr_matrix
import numpy as np
rows = csr_data['row_new'].values - 1
cols = csr_data['col_new'].values - 1
vals = csr_data['value'].values
X_csr = csr_matrix((vals, (rows, cols)))X_csr.shape(11009, 79)X_csr.shape, X_csr.nnz((11009, 79), 132142)X_csr.nnz / (X_csr.shape[0]* X_csr.shape[1]) # 0152347 * 92)0.15193782762319896# The label vector. Let's make it dense, flat and binary
y = np.array(X_csr[:, 1].todense()).ravel()
y = np.array(y > 0, dtype=np.int64)X_csr.shape(11009, 79)# We remove the second and fourth column.
# It actually contain the label we'll want to predict.
kept_cols = list(range(X_csr.shape[1]))
kept_cols.pop(1)
kept_cols.pop(2)
X = X_csr[:, kept_cols]len(kept_cols)77X_csr.shape, X.shape((11009, 79), (11009, 77))Wow ! That was a lot of work. Now we have a features matrix \(X\) and a vector of labels \(y\).
X.indicesarray([ 1, 3, 4, ..., 68, 75, 76], shape=(121120,), dtype=int32)X.indptrarray([ 0, 14, 24, ..., 121100, 121110, 121120],
shape=(11010,), dtype=int32)X.shape, X.nnz((11009, 77), 121120)y.shape, y.sum()((11009,), np.int64(73))from sklearn.preprocessing import MaxAbsScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# Normalize the features
X = MaxAbsScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.3)
clf = LogisticRegression(
penalty='l2',
C=1e3,
solver='lbfgs',
class_weight='balanced'
)
clf.fit(X_train, y_train)LogisticRegression(C=1000.0, class_weight='balanced')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
LogisticRegression(C=1000.0, class_weight='balanced')
features_names = features_names.toPandas()['feature_name']25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:47 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:48 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:48 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:48 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
25/05/12 10:25:48 WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.features_names[range(6)]0 n_actions_per_category_id#C#1002.0
1 n_actions_per_category_id#C#1204.0
2 n_actions_per_category_id#O#1002.0
3 n_actions_per_category_id#O#1204.0
4 n_days_since_last_action#C
5 n_days_since_last_action#O
Name: feature_name, dtype: objectimport matplotlib.pyplot as plt
%matplotlib inlineplt.figure(figsize=(16, 5))
plt.stem(clf.coef_[0]) # , use_line_collection=True)
plt.title('Logistic regression coefficients', fontsize=18)Text(0.5, 1.0, 'Logistic regression coefficients')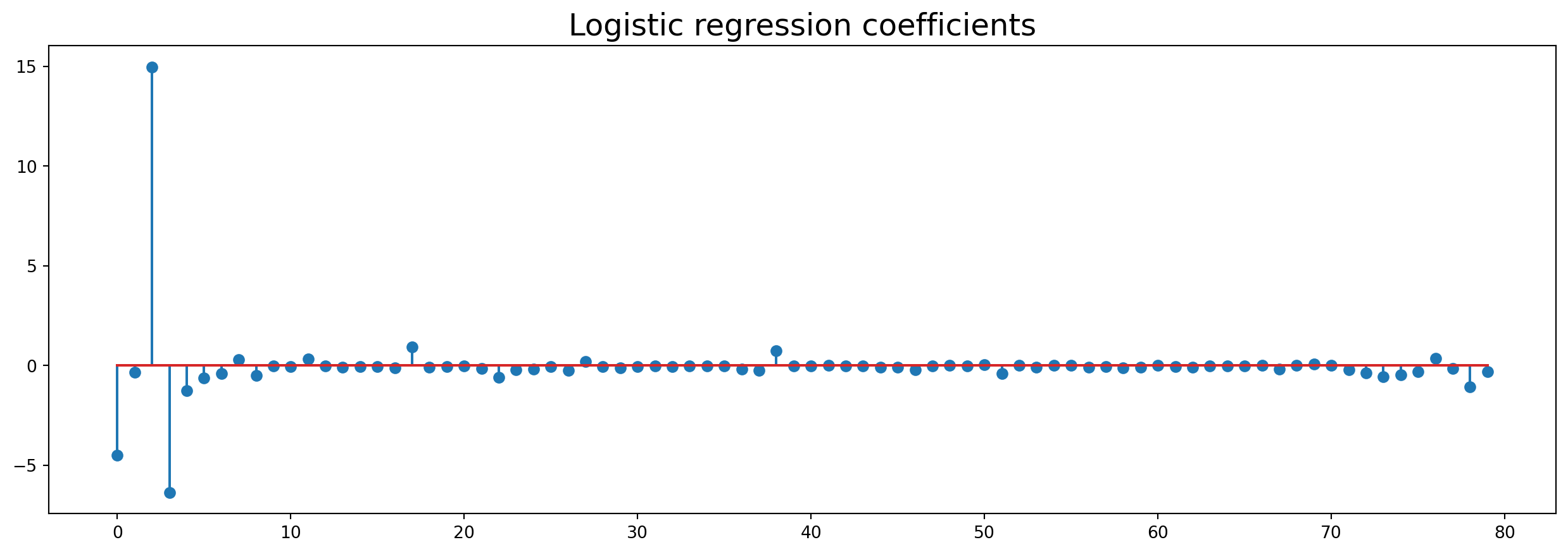
clf.coef_[0].shape[0]77len(features_names)79# We change the fontsize of minor ticks label
_ = plt.xticks(np.arange(clf.coef_[0].shape[0]), features_names,
rotation='vertical', fontsize=8)_ = plt.yticks(fontsize=14)
from sklearn.metrics import precision_recall_curve, f1_score
precision, recall, _ = precision_recall_curve(y_test, clf.predict_proba(X_test)[:, 1])
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, label='LR (F1=%.2f)' % f1_score(y_test, clf.predict(X_test)), lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Recall', fontsize=16)
plt.ylabel('Precision', fontsize=16)
plt.title('Precision/recall curve', fontsize=18)
plt.legend(loc="upper right", fontsize=14)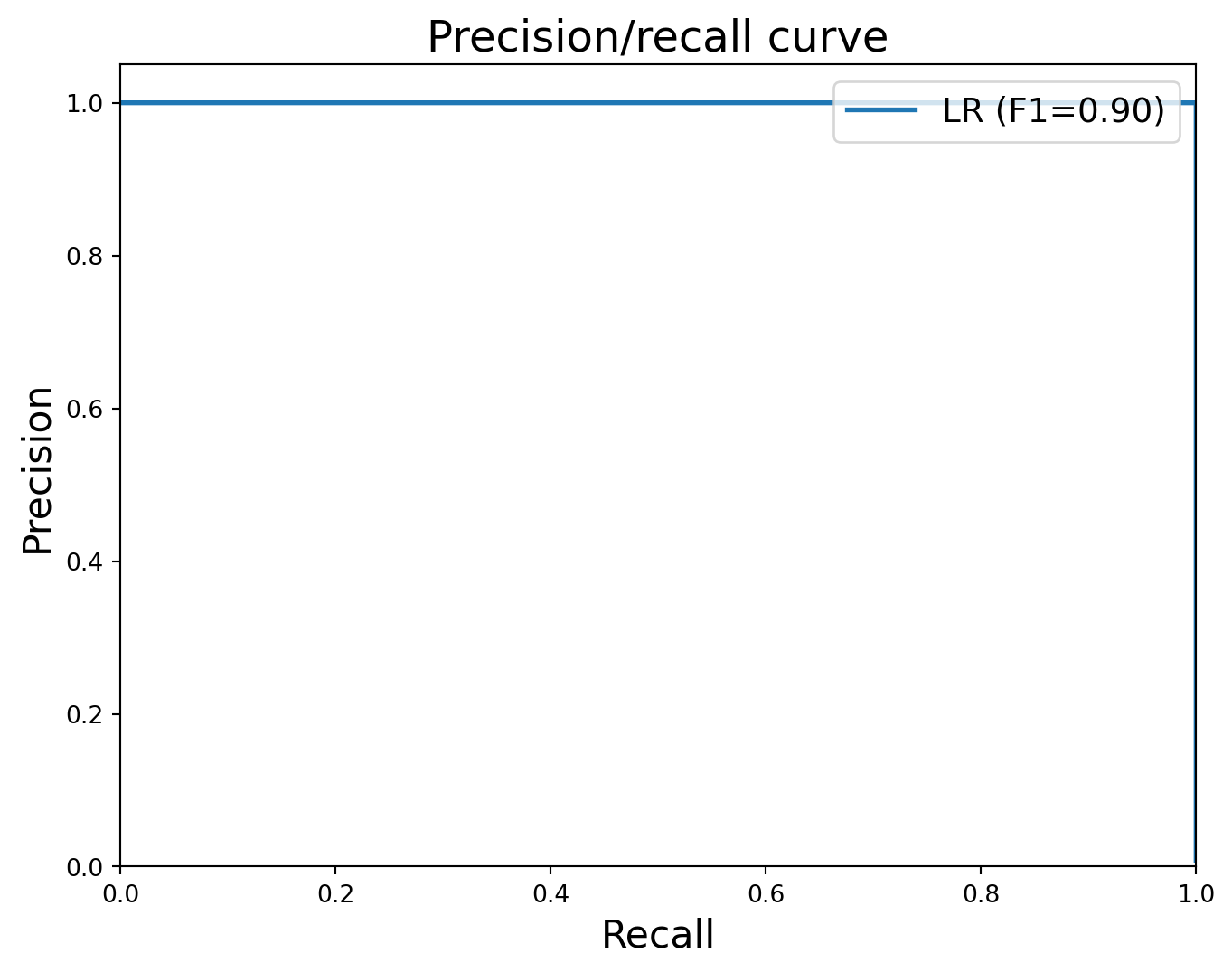
query = """ANALYZE TABLE db_table COMPUTE STATISTICS
FOR COLUMNS xid"""df.createOrReplaceTempView("db_table")df.columns['xid',
'value',
'feature_name',
'col',
'row',
'keep',
'sum_keep',
'row_new',
'col_new']spark.sql("cache table db_table")spark.sql(query)spark.sql("show tables")