Dask
Technologies Big Data Master MIDS/MFA/LOGOIS
2025-01-17
Bird-eye Big Picture
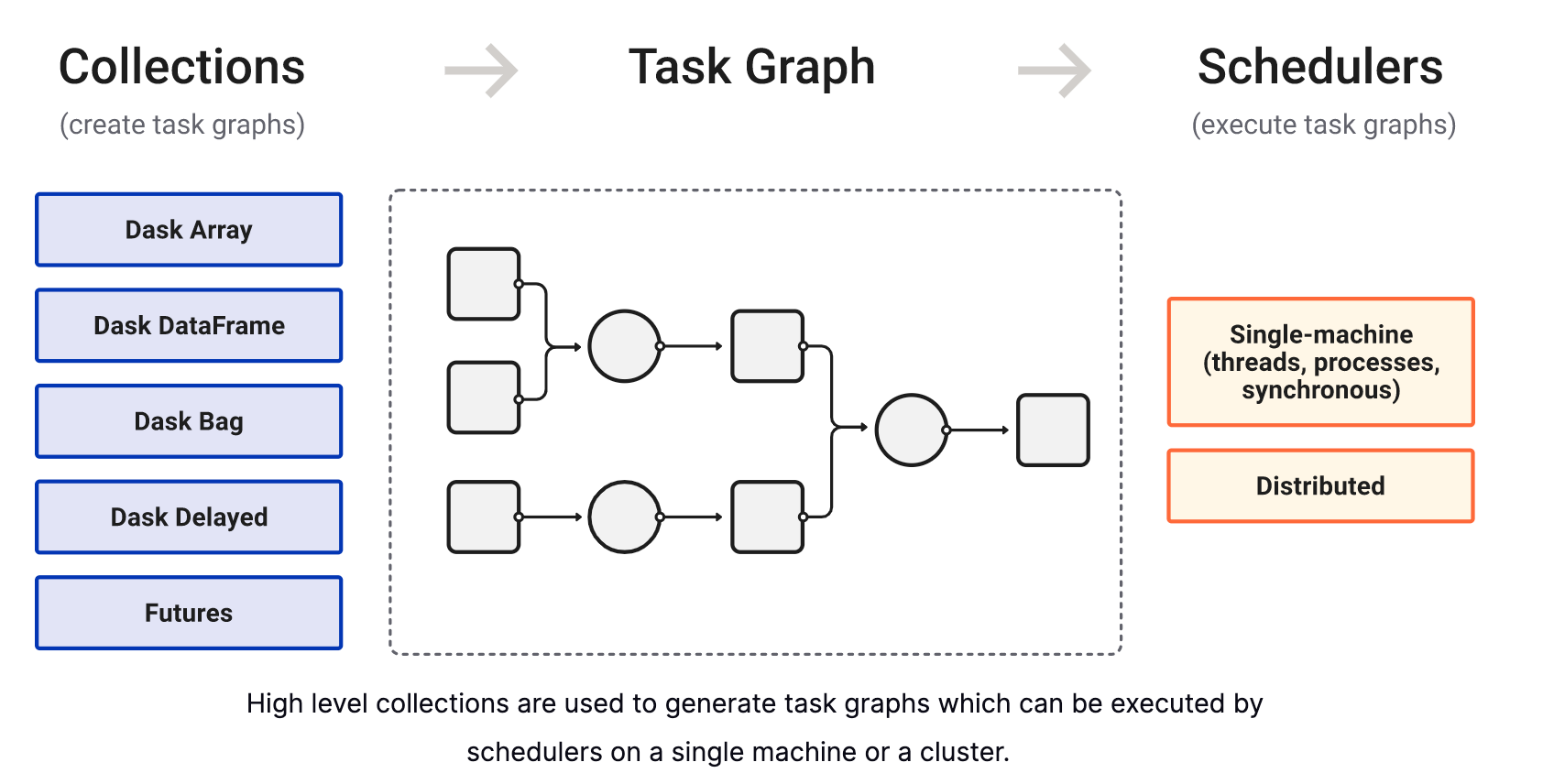
Dask in picture

Dask provides multi-core and distributed parallel execution on larger-than-memory datasets
Dask provides high-level Array, Bag, and DataFrame collections that mimic NumPy, lists, and Pandas but can operate in parallel on datasets that do not fit into memory
Dask provides dynamic task schedulers that execute task graphs in parallel.
These schedulers/execution engines power the high-level collections but can also power custom, user-defined workloads
These schedulers are low-latency and work hard to run computations in a small memory footprint
Trends
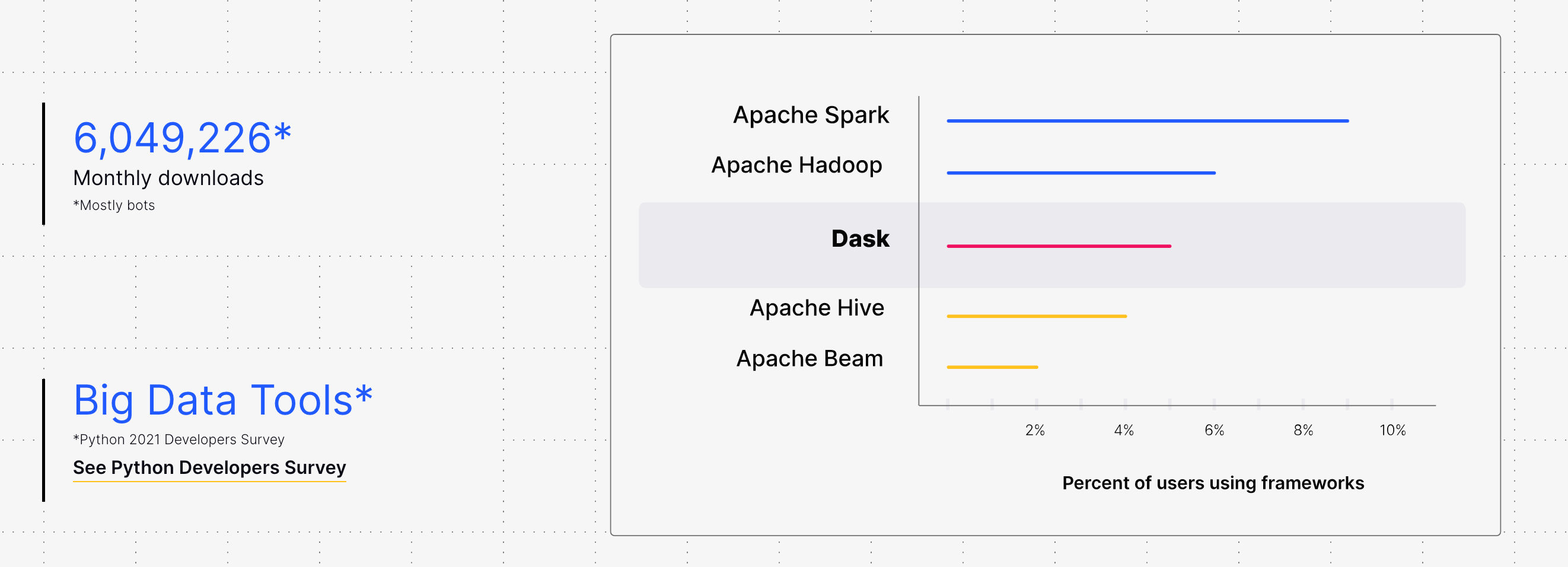
Dask adoption metrics
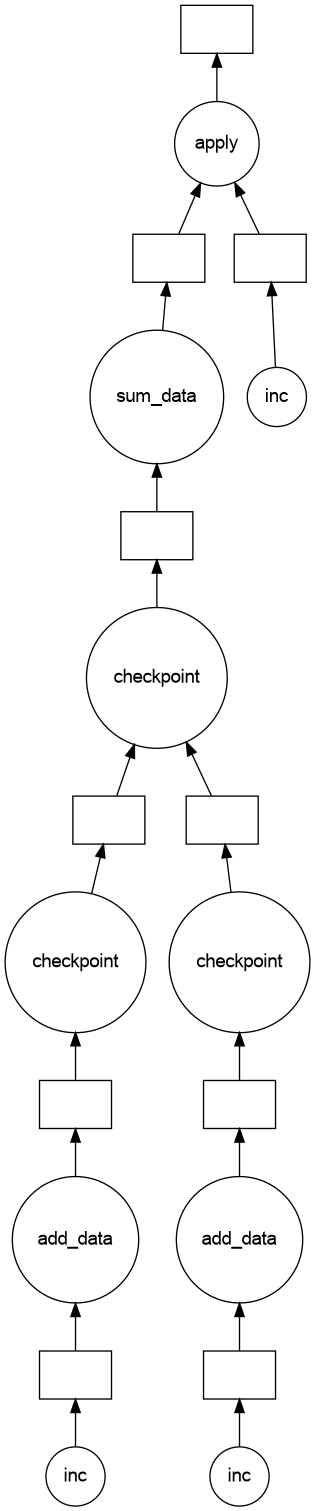
Visualizing the task graph
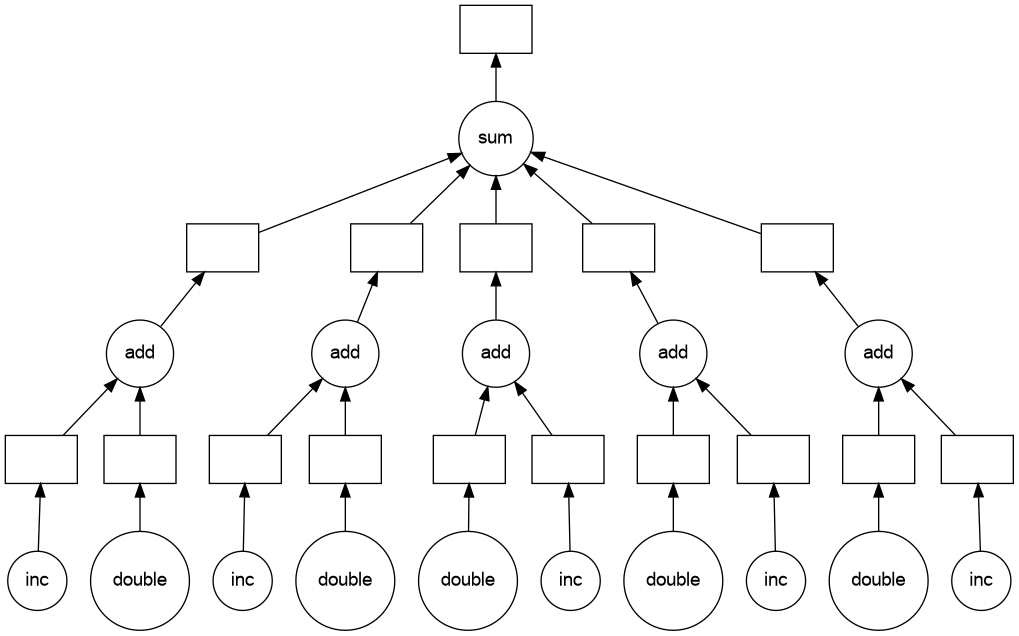
A flawed task graph
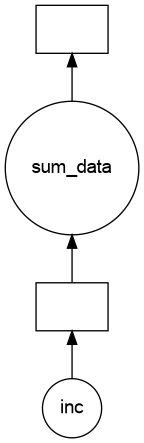
Fixing
12The result of the evaluation of sum_data() depends not only on its argument, hence on the Delayed e, but also on the side effects of add_data(), that is on the Delayed b and d
Note that not only the DAG was wrong but the result obtained above was not the intended result.
Dask DataFrame helps you process large tabular data by parallelizing Pandas, either on your laptop for larger-than-memory computing, or on a distributed cluster of computers.

Just
pandas: Dask DataFrames are a collection of manypandasDataFrames.
The API is the same1. The execution is the same
Large scale: Works on 100 GiB on a laptop, or 100 TiB on a cluster.
Easy to use: Pure Python, easy to set up and debug.
Dask DataFrames coordinate many pandas DataFrames/Series arranged along the index. A Dask DataFrame is partitioned row-wise, grouping rows by index value for efficiency. These pandas objects may live on disk or on other machines.
Inside the dataframe
A sketch of the interplay between index and partitioning
(Timestamp('2021-09-01 00:00:00'),
Timestamp('2021-09-06 00:00:00'),
Timestamp('2021-09-11 00:00:00'),
Timestamp('2021-09-16 00:00:00'),
Timestamp('2021-09-21 00:00:00'),
Timestamp('2021-09-26 00:00:00'),
Timestamp('2021-10-01 00:00:00'),
Timestamp('2021-10-06 00:00:00'),
Timestamp('2021-10-11 00:00:00'),
Timestamp('2021-10-16 00:00:00'),
Timestamp('2021-10-21 00:00:00'),
Timestamp('2021-10-26 00:00:00'),
Timestamp('2021-10-31 00:00:00'),
Timestamp('2021-11-05 00:00:00'),
Timestamp('2021-11-10 00:00:00'),
Timestamp('2021-11-15 00:00:00'),
Timestamp('2021-11-20 00:00:00'),
Timestamp('2021-11-25 00:00:00'),
Timestamp('2021-11-30 00:00:00'),
Timestamp('2021-12-05 00:00:00'),
Timestamp('2021-12-09 23:00:00'))A dataframe has a task graph

TODO
What’s in a partition?
| a | b | |
|---|---|---|
| npartitions=1 | ||
| 2021-09-06 | int64 | string |
| 2021-09-11 | ... | ... |
Slicing
| a | b | |
|---|---|---|
| npartitions=2 | ||
| 2021-10-01 00:00:00.000000000 | int64 | string |
| 2021-10-06 00:00:00.000000000 | ... | ... |
| 2021-10-09 05:00:59.999999999 | ... | ... |
Dask Series Structure:
npartitions=1
float64
...
Dask Name: getitem, 4 expressions
Expr=((ReadParquetFSSpec(117185e)[['passenger_count', 'tip_amount']]).mean(observed=False, chunk_kwargs={'numeric_only': False}, aggregate_kwargs={'numeric_only': False}, _slice='tip_amount'))['tip_amount']Client
Client-23ac4916-e27e-11ef-a64c-300505fc3398
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
62d0ccd4
| Dashboard: http://127.0.0.1:8787/status | Workers: 5 |
| Total threads: 20 | Total memory: 30.96 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-4a341215-7814-4fde-a35c-f90f4492536c
| Comm: tcp://127.0.0.1:45181 | Workers: 5 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 20 |
| Started: Just now | Total memory: 30.96 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:34133 | Total threads: 4 |
| Dashboard: http://127.0.0.1:39875/status | Memory: 6.19 GiB |
| Nanny: tcp://127.0.0.1:46805 | |
| Local directory: /tmp/dask-scratch-space/worker-31p6doxl | |
Worker: 1
| Comm: tcp://127.0.0.1:41389 | Total threads: 4 |
| Dashboard: http://127.0.0.1:37229/status | Memory: 6.19 GiB |
| Nanny: tcp://127.0.0.1:43601 | |
| Local directory: /tmp/dask-scratch-space/worker-m9q13h76 | |
Worker: 2
| Comm: tcp://127.0.0.1:34985 | Total threads: 4 |
| Dashboard: http://127.0.0.1:41965/status | Memory: 6.19 GiB |
| Nanny: tcp://127.0.0.1:34219 | |
| Local directory: /tmp/dask-scratch-space/worker-1yjf2_ei | |
Worker: 3
| Comm: tcp://127.0.0.1:35209 | Total threads: 4 |
| Dashboard: http://127.0.0.1:33913/status | Memory: 6.19 GiB |
| Nanny: tcp://127.0.0.1:42609 | |
| Local directory: /tmp/dask-scratch-space/worker-_sj1rvoz | |
Worker: 4
| Comm: tcp://127.0.0.1:42041 | Total threads: 4 |
| Dashboard: http://127.0.0.1:45571/status | Memory: 6.19 GiB |
| Nanny: tcp://127.0.0.1:35539 | |
| Local directory: /tmp/dask-scratch-space/worker-tgi7deul | |