Apache and RDD
Technologies Big Data Master MIDS/MFA/LOGOIS
2025-01-17
Introduction
Principles
Spark computing framework deals with many complex issues: fault tolerance, slow machines, big datasets, etc.
It follows the next guideline
Here is an operation, run it on all the data.
Note
- I do not care where it runs
- Feel free to run it twice on different nodes
Jobs are divided in tasks that are executed by the workers
Note
- How do we deal with failure? Launch another task!
- How do we deal with stragglers? Launch another task!
… and kill the original task
A picture
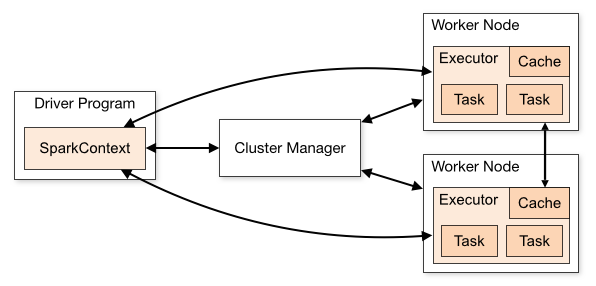
Spark Cluster Overview
Job
A job in Spark represents a complete computation triggered by an action in the application code.
When you invoke an action (such as collect(), saveAsTextFile(), etc.) on a Spark RDD, DataFrame, or Dataset, it triggers the execution of one or more jobs.
Each job consists of one or more stages, where each stage represents a set of tasks that can be executed in parallel.
Jobs in Spark are created by transformations that have no dependency on each other, meaning each stage can execute independently.
Task
A task is the smallest unit of work in Spark and represents the execution of a computation on a single partition of data.
Tasks are created for each partition of the RDD, DataFrame, or Dataset involved in the computation.
Spark’s execution engine assigns tasks to individual executor nodes in the cluster for parallel execution.
Tasks are executed within the context of a specific stage, and each task typically operates on a subset of the data distributed across the cluster.
The number of tasks within a stage depends on the number of partitions of the input data and the degree of parallelism configured for the Spark application.
In summary, a job represents the entire computation triggered by an action, composed of one or more stages, each of which is divided into smaller units of work called tasks.
Tasks operate on individual partitions of the data in parallel to achieve efficient and scalable distributed computation in Spark.
API
An API allows a user to interact with the software
Spark is implemented in Scala and runs on the JVM (Java Virtual Machine)
Multiple Application Programming Interfaces (APIs):
Scala(JVM)Java(JVM)-
Python -
R
This course uses primarily the Python API. Easier to learn than Scala and Java
About the R APIs
Digression on acronym API (Application Programming Interface)
See https://en.wikipedia.org/wiki/API for more on this acronym
In Python language, look at interface and corresponding chapter Interfaces, Protocols and ABCs in Fluent Python
For R there are in fact two APIs, or two packages that offer a Spark API
See Mastering Spark with R by Javier Luraschi, Kevin Kuo, Edgar Ruiz
Architecture
When you interact with Spark through its API, you send instructions to the Driver
- The Driver is the central coordinator
- It communicates with distributed workers called executors
- Creates a logical directed acyclic graph (DAG) of operations
- Merges operations that can be merged
- Splits the operations in tasks (smallest unit of work in Spark)
- Schedules the tasks and send them to the executors
- Tracks data and tasks
Example
- Example of DAG:
map(f) - map(g) - filter(h) - reduce(l) map(f o g)
SparkSession and SparkContext
SparkContext versus SparkSession
SparkContext and SparkSession serve different purposes
SparkContext was the main entry point for Spark applications in first versions of Apache Spark.
SparkContext represented the connection to a Spark cluster, allowing the application to interact with the cluster manager.
SparkContext was responsible for coordinating and managing the execution of jobs and tasks.
SparkContext provided APIs for creating RDDs (Resilient Distributed Datasets), which were the primary abstraction in Spark for representing distributed data.
SparkContext object
Your python session interacts with the driver through a SparkContext object
In the
Sparkinteractive shell
An object of classSparkContextis automatically created in the session and namedscIn a
jupyter notebook
Create aSparkContextobject using:
SparkSession
In Spark 2.0 and later versions, SparkContext is still available but is not the primary entry point.
Instead, SparkSession is preferred.
SparkSession was introduced in Spark 2.0 as a higher-level abstraction that encapsulates SparkContext, SQLContext, and HiveContext.
SparkSession provides a unified entry point for Spark functionality, integrating Structured APIs:
SQL,DataFrame,Dataset
and the traditional RDD-based APIs.
What SparkSession?
SparkSession is designed to make it easier to work with structured data (like data stored in tables or files with a schema) using Spark’s DataFrame and Dataset APIs.
SparkSession also provides built-in support for reading data from various sources (like Parquet, JSON, JDBC, etc.) into DataFrames and writing DataFrames back to different formats.
Additionally, SparkSession simplifies the configuration of Spark properties and provides a Spark SQL CLI and a Spark Shell with SQL and DataFrame support.
Note
SparkSession internally creates and manages a SparkContext, so when you create a SparkSession, you don’t need to create a SparkContext separately.
SparkContext is lower-level and primarily focused on managing the execution of Spark jobs and interacting with the cluster
SparkSession provides a higher-level, more user-friendly interface for working with structured data and integrates various Spark functionalities, including SQL, DataFrame, and Dataset APIs.
RDDs and running model
Spark programs are written in terms of operations on RDDs
RDD stands for Resilient Distributed Dataset
An immutable distributed collection of objects spread across the cluster disks or memory
RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes
Parallel transformations and actions can be applied to RDDs
RDDs are automatically rebuilt on machine failure
Creating a RDD
From an iterable object iterator1 (e.g. a Python list, etc.):
From a text file:
where lines is the resulting RDD, and sc the spark context
Remarks
parallelizenot really used in practice- In real life: load data from external storage
- External storage is often HDFS (Hadoop Distributed File System)
- Can read most formats (
json,csv,xml,parquet,orc, etc.)
Operations on RDD
Two families of operations can be performed on RDDs
- Transformations
Operations on RDDs which return a new RDD
Lazy evaluation
- Actions
Operations on RDDs that return some other data type
Triggers computations
When a transformation is called on a RDD:
- The operation is not immediately performed
- Spark internally records that this operation has been requested
- Computations are triggered only if an action requires the result of this transformation at some point
Transformations
Transformations
The most important transformation is map
| transformation | description |
|---|---|
map(f) |
apply a function f to each element of the RDD |
Here is an example:
- We have to call
collect(an action) otherwise nothing happens - Once again, transformation
mapis lazily evaluated
Note
- In
Python, three options for passing functions intoSpark- for short functions:
lambdaexpressions (anonymous functions) - top-level functions
- locally/user defined functions with
def
- for short functions:
Transformations
Passing functions to map:
- Involves serialization with
pickle Sparksends the entire pickled function to worker nodes
Warning
If the function is an object method:
- The whole object is pickled since the method contains references to the object (
self) and references to attributes of the object - The whole object can be large
- The whole object may not be serializable with
pickle
Python’s corner
Serialization
Converting an object from its in-memory structure to a binary or text-oriented format for storage or transmission, in a way that allows the future reconstruction of a clone of the object on the same system or on a different one.
The
picklemodule supports serialization of arbitraryPythonobjects to a binary format
from Fluent Python by Ramalho
Transformations (continued)
flatMap
| transformation | description |
|---|---|
flatMap(f) |
apply f to each element of the RDD, then flattens the results |
Python’s corner: is there any flatMap() function?
Nested list comprehensions
[1, 1, 2, 1, 2, 3]Transformations (continued)
filter allows to filter an RDD
| transformation | description |
|---|---|
filter(f) |
Return an RDD consisting of only elements that pass the condition f passed to filter() |
Python’s corner
Using list comprehensions
Transformations: distinct and sample
| transformation | description |
|---|---|
distinct() |
Removes duplicates |
sample(withReplacement, fraction, [seed]) |
Sample an RDD, with or without replacement |
Python’s corner
Transformations
We have also pseudo-set-theoretical operations
| transformation | description |
|---|---|
union(otherRdd) |
Returns union with otherRdd |
instersection(otherRdd) |
Returns intersection with otherRdd |
subtract(otherRdd) |
Return each value in self that is not contained in otherRdd. |
Note
- If there are duplicates in the input RDD, the result of
union()will contain duplicates (fixed withdistinct()) intersection()removes all duplicates (including duplicates from a single RDD)- Performance of
intersection()is much worse thanunion()since it requires a shuffle to identify common elements subtractalso requires a shuffle
Transformations
We have also pseudo-set-theoretical operations
| transformation | description |
|---|---|
union(otherRdd) |
Returns union with otherRdd |
instersection(otherRdd) |
Returns intersection with otherRdd |
subtract(otherRdd) |
Return each value in self that is not contained in otherRdd. |
Python’s corner
About shuffles
- Certain operations trigger a shuffle
- It is
Spark’s mechanism for redistributing data so as to modify the partitioning - It involves moving data across executors and machines, making shuffle a complex and costly operation
- More on shuffles later
Performance Impact
- A shuffle involves
- disk I/O,
- data serialization
- network I/O.
- To organize data for the shuffle,
Sparkgenerates sets of tasks:- map tasks to organize the data and
- reduce tasks to aggregate it
Transformations
Another pseudo set operation
| transformation | description |
|---|---|
cartesian(otherRdd) |
Return the Cartesian product of this RDD and another one |
Actions
Actions
collect() brings the RDD back to the driver
| transformation | description |
|---|---|
collect() |
Return all elements from the RDD |
Example
- Be sure that the retrieved data fits in the driver memory !
- Useful when developping and working on small data for testing
- We’ll use it a lot here, but we don’t use it in real-world problems
Actions
Counts matter!
| transformation | description |
|---|---|
count() |
Return the number of elements in the RDD |
countByValue() |
Return the count of each unique value in the RDD as a dictionary of {value: count} pairs. |
Python’s corner
Actions: cherry-picking
How to get some (but not all) values in an RDD ?
| action | description |
|---|---|
take(n) |
Return n elements from the RDD (deterministic) |
top(n) |
Return first n elements from the RDD (descending order) |
takeOrdered(num, key=None) |
Get the N elements from a RDD ordered in ascending order or as specified by the optional key function. |
Note
take(n)returns n elements from the RDD and attempts to minimize the number of partitions it accesses- the result may be a biased collection
collectandtakemay return the elements in an order you don’t expect
Python’s corner
Actions
How to get some values in an RDD?
| action | description |
|---|---|
take(n) |
Return n elements from the RDD (deterministic) |
top(n) |
Return first n elements from the RDD (decending order) |
takeOrdered(num, key=None) |
Get the $N $elements from a RDD ordered in ascending order or as specified by the optional key function. |
Actions: reduction(s)
| action | description |
|---|---|
reduce(f) |
Reduces the elements of this RDD using the specified commutative and associative binary operator f. |
fold(zeroValue, op) |
Same as reduce() but with the provided zero value. |
op(x, y)is allowed to modify x and return it as its result value to avoid object allocation; however, it should not modify y.reduceapplies some operation to pairs of elements until there is just one left. Throws an exception for empty collections.foldhas initial zero-value: defined for empty collections.
Actions: reduction(s)
| action | description |
|---|---|
reduce(f) |
Reduces the elements of this RDD using the specified commutative and associative binary operator f. |
fold(zeroValue, op) |
Same as reduce() but with the provided zero value. |
Actions: reduction(s)
| action | description |
|---|---|
reduce(f) |
Reduces the elements of this RDD using the specified commutative and associative binary operator f. |
fold(zeroValue, op) |
Same as reduce() but with the provided zero value. |
Warning
With fold, solutions can depend on the number of partitions
- RDD has 2 partition: say [1, 2] and [4]
- Sum in the partitions: 2.5 + (1 + 2) = 5.5 and 2.5 + (4) = 6.5
- Sum over partitions: 2.5 + (5.5 + 6.5) = 14.5
Actions: reduction(s)
| action | description |
|---|---|
reduce(f) |
Reduces the elements of this RDD using the specified commutative and associative binary operator f. |
fold(zeroValue, op) |
Same as reduce() but with the provided zero value. |
Actions: reduction(s)
| action | description |
|---|---|
reduce(f) |
Reduces the elements of this RDD using the specified commutative and associative binary operator f. |
fold(zeroValue, op) |
Same as reduce() but with the provided zero value. |
Python’s corner
Actions : aggregate
| action | description |
|---|---|
aggregate(zero, seqOp, combOp) |
Similar to reduce() but used to return a different type |
Aggregates the elements of each partition, and then the results for all the partitions, given aggregation functions and zero value.
seqOp(acc, val): function to combine the elements of a partition from the RDD (val) with an accumulator (acc).
The result type may differ from theRDDtype (if any)combOp: function that merges the accumulators of two partitions- In both functions, the first argument can be modified while the second cannot
Actions : aggregate
| action | description |
|---|---|
aggregate(zero, seqOp, combOp) |
Similar to reduce() but used to return a different type |
Actions
The foreach action
| action | description |
|---|---|
foreach(f) |
Apply a function f to each element of a RDD |
Performs an action on all of the elements in the RDD without returning any result to the driver.
Example : insert records into a database with
f
The foreach() action performs computations on each element of the RDD without bringing it back to the driver
Persistence
Lazy evaluation and persistence
Spark RDDs are lazily evaluated
Each time an action is called on a RDD, this RDD and all its dependencies are recomputed
If you plan to reuse a RDD multiple times, you should use persistence
Note
- Lazy evaluation helps
sparkto reduce the number of passes over the data it has to make by grouping operations together - No substantial benefit to writing a single complex map instead of chaining together many simple operations
- Users are free to organize their program into smaller, more manageable operations
Persistence
How to use persistence ?
| method | description |
|---|---|
cache() |
Persist the RDD in memory |
persist(storageLevel) |
Persist the RDD according to storageLevel |
These methods must be called before the action, and do not trigger the actual computation
Usage of storageLevel
Shades of persistence
- What does persistence in memory mean?
- Make
StorageLevelexplicit - Any difference between
cache()andpersist()withuseMemory? - Why do we call persistence caching?
Options for persistence
Options for persistence
| argument | description |
|---|---|
useDisk |
Allow caching to use disk if True |
useMemory |
Allow caching to use memory if True |
useOffHeap |
Store data outside of JVM heap if True. Useful if using some in-memory storage system (such a Tachyon) |
deserialized |
Cache data without serialization if True |
replication |
Number of replications of the cached data |
replication: If you are caching data that is expensive to compute, you can use replication. If one machine fails, data does not need to be recomputed.
Options for persistence
Options for persistence
| argument | description |
|---|---|
useDisk |
Allow caching to use disk if True |
useMemory |
Allow caching to use memory if True |
useOffHeap |
Store data outside of JVM heap if True. Useful if using some in-memory storage system (such a Tachyon) |
deserialized |
Cache data without serialization if True |
replication |
Number of replications of the cached data |
deserialized :
- Serialization consists in converting data to some binary format
- To the best of our knowledge,
PySparkonly support serialized caching (usingpickle)
Options for persistence
Options for persistence
| argument | description |
|---|---|
useDisk |
Allow caching to use disk if True |
useMemory |
Allow caching to use memory if True |
useOffHeap |
Store data outside of JVM heap if True. Useful if using some in-memory storage system (such a Tachyon) |
deserialized |
Cache data without serialization if True |
replication |
Number of replications of the cached data |
useOffHeap
- Data cached in the JVM heap by default
- Very interesting alternative in-memory solutions such as
tachyon - Don’t forget that
sparkisscalarunning on the JVM
Back to options for persistence
You can use these constants:
DISK_ONLY = StorageLevel(True, False, False, False, 1)
DISK_ONLY_2 = StorageLevel(True, False, False, False, 2)
MEMORY_AND_DISK = StorageLevel(True, True, False, True, 1)
MEMORY_AND_DISK_2 = StorageLevel(True, True, False, True, 2)
MEMORY_AND_DISK_SER = StorageLevel(True, True, False, False, 1)
MEMORY_AND_DISK_SER_2 = StorageLevel(True, True, False, False, 2)
MEMORY_ONLY = StorageLevel(False, True, False, True, 1)
MEMORY_ONLY_2 = StorageLevel(False, True, False, True, 2)
MEMORY_ONLY_SER = StorageLevel(False, True, False, False, 1)
MEMORY_ONLY_SER_2 = StorageLevel(False, True, False, False, 2)
OFF_HEAP = StorageLevel(False, False, True, False, 1)and simply call for instance
Persistence
What if you attempt to cache too much data to fit in memory ?
Spark will automatically evict old partitions using a Least Recently Used (LRU) cache policy:
For the memory-only storage levels, it will recompute these partitions the next time they are accessed
For the memory-and-disk ones, it will write them out to disk
Use unpersist() to RDDs to manually remove them from the cache
Reminder: about passing functions
Warning
When passing functions, you can inadvertently serialize the object containing the function.
If you pass a function that:
- is the member of an object (a method)
- contains references to fields in an object
then Spark sends the entire object to worker nodes, which can be much larger than the bit of information you need
Caution
This can cause your program to fail, if your class contains objects that Python can’t pickle
About passing functions
Passing a function with field references (don’t do this ! )
class SearchFunctions(object):
def __init__(self, query):
self.query = query
def isMatch(self, s):
return self.query in s
def getMatchesFunctionReference(self, rdd):
# Problem: references all of "self" in "self.isMatch"
return rdd.filter(self.isMatch)
def getMatchesMemberReference(self, rdd):
# Problem: references all of "self" in "self.query"
return rdd.filter(lambda x: self.query in x)Tip
Instead, just extract the fields you need from your object into a local variable and pass that in
About passing functions
Python function passing without field references
Much better!
Pair RDD: key-value pairs
Pair RDD: key-value pairs
It’s roughly a RDD where each element is a tuple with two elements: a key and a value
- For numerous tasks, such as aggregations tasks, storing information as
(key, value)pairs into RDD is very convenient - Such RDDs are called
PairRDD - Pair RDDs expose new operations such as grouping together data with the same key, and grouping together two different RDDs
Creating a pair RDD
Calling map with a function returning a tuple with two elements
Warning
All elements of a PairRDD must be tuples with two elements (the key and the value)
Transformations for a single PairRDD
| transformation | description |
|---|---|
keys() |
Return an RDD containing the keys |
values() |
Return an RDD containing the values |
sortByKey() |
Return an RDD sorted by the key |
mapValues(f) |
Apply a function f to each value of a pair RDD without changing the key |
flatMapValues(f) |
Pass each value in the key-value pair RDD through a flatMap function f without changing the keys |
Transformations for a single PairRDD
| transformation | description |
|---|---|
keys() |
Return an RDD containing the keys |
values() |
Return an RDD containing the values |
sortByKey() |
Return an RDD sorted by the key |
mapValues(f) |
Apply a function f to each value of a pair RDD without changing the key |
flatMapValues(f) |
Pass each value in the key-value pair RDD through a flatMap function f without changing the keys |
Transformations for a single PairRDD
| transformation | description |
|---|---|
keys() |
Return an RDD containing the keys |
values() |
Return an RDD containing the values |
sortByKey() |
Return an RDD sorted by the key |
mapValues(f) |
Apply a function f to each value of a pair RDD without changing the key |
flatMapValues(f) |
Pass each value in the key-value pair RDD through a flatMap function f without changing the keys |
Transformations for a single PairRDD (keyed)
| transformation | description |
|---|---|
groupByKey() |
Group values with the same key |
reduceByKey(f) |
Merge the values for each key using an associative reduce function f. |
foldByKey(f) |
Merge the values for each key using an associative reduce function f. |
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner]) |
Generic function to combine the elements for each key using a custom set of aggregation functions. |
Transformations for a single PairRDD (keyed)
| transformation | description |
|---|---|
groupByKey() |
Group values with the same key |
reduceByKey(f) |
Merge the values for each key using an associative reduce function f. |
foldByKey(f) |
Merge the values for each key using an associative reduce function f. |
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner]) |
Generic function to combine the elements for each key using a custom set of aggregation functions. |
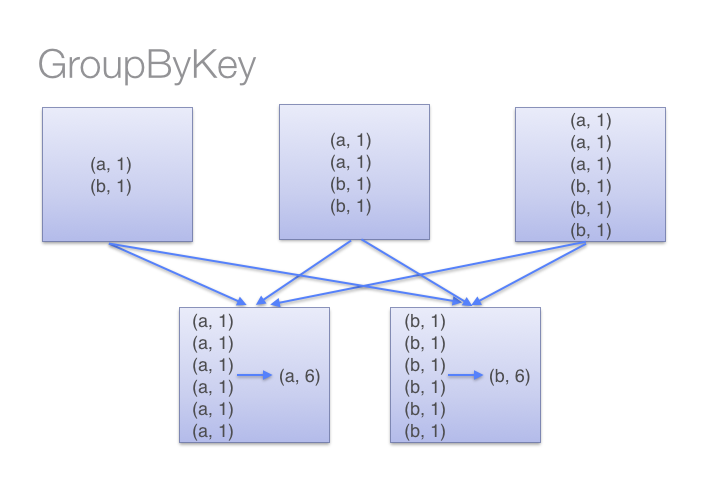
groupByKey() internals
- Grouping locally
- Shuffling
- Partitionning
- Relation to
reduceByKey()
Transformations for a single PairRDD (keyed)
| transformation | description |
|---|---|
groupByKey() |
Group values with the same key |
reduceByKey(f) |
Merge the values for each key using an associative reduce function f. |
foldByKey(f) |
Merge the values for each key using an associative reduce function f. |
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner]) |
Generic function to combine the elements for each key using a custom set of aggregation functions. |
ReduceByKey in picture
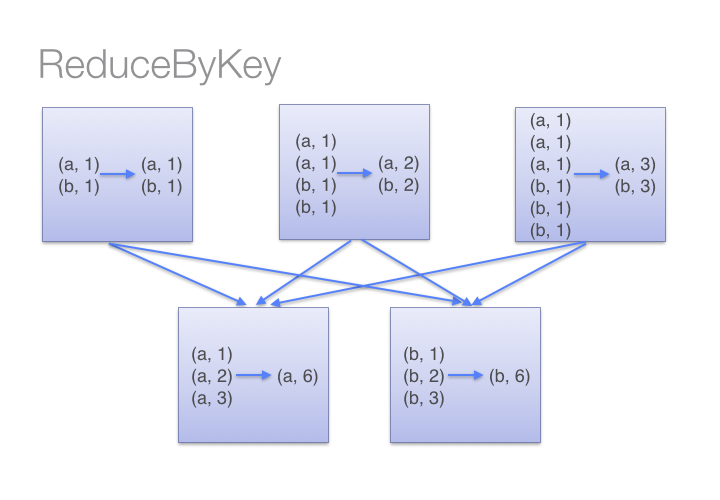
Transformations for a single PairRDD (keyed)
| transformation | description |
|---|---|
groupByKey() |
Group values with the same key |
reduceByKey(f) |
Merge the values for each key using an associative reduce function f. |
foldByKey(f) |
Merge the values for each key using an associative reduce function f. |
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner]) |
Generic function to combine the elements for each key using a custom set of aggregation functions. |
combineByKey Transforms an RDD[(K, V)] into another RDD of type RDD[(K, C)] for a combined type C that can be different from V
The user must define
createCombiner: which turns aVinto aCmergeValue: to merge aVinto aCmergeCombiners: to combine twoC’s into a single one
Transformations for a single PairRDD (keyed)
| transformation | description |
|---|---|
groupByKey() |
Group values with the same key |
reduceByKey(f) |
Merge the values for each key using an associative reduce function f. |
foldByKey(f) |
Merge the values for each key using an associative reduce function f. |
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner]) |
Generic function to combine the elements for each key using a custom set of aggregation functions. |
Transformations for two PairRDD
| transformation | description |
|---|---|
subtractByKey(other) |
Remove elements with a key present in the other RDD. |
join(other) |
Inner join with other RDD. |
rightOuterJoin(other) |
Right join with other RDD. |
leftOuterJoin(other) |
Left join with other RDD. |
- Right join: the key must be present in the first RDD
- Left join: the key must be present in the
otherRDD
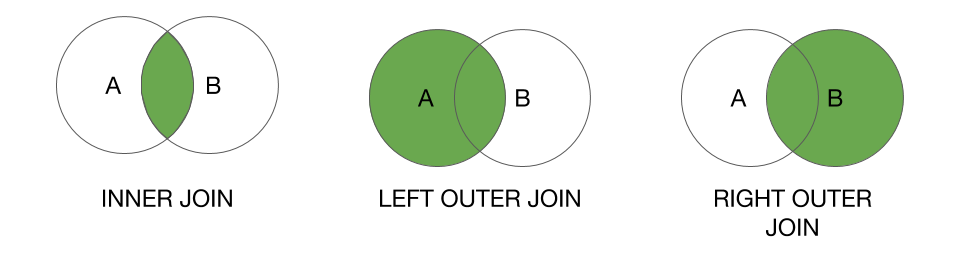
Transformations for two PairRDD
Join operations are mainly used through the high-level API:
DataFrameobjects and thespark.sqlAPIWe will use them a lot with the high-level API (
DataFramefromspark.sql)
Actions for a single PairRDD
| action | description |
|---|---|
countByKey() |
Count the number of elements for each key. |
lookup(key) |
Return all the values associated with the provided key. |
collectAsMap() |
Return the key-value pairs in this RDD to the master as a Python dictionary. |
Data partitionning
- Some operations on
PairRDDs, such asjoin, require to scan the data more than once - Partitionning the RDDs in advance can reduce network communications
- When a key-oriented dataset is reused several times, partitionning can improve performance
- In
Spark: you can choose which keys will appear on the same node, but no explicit control of which worker node each key goes to.
Data partitionning
In practice, you can specify the number of partitions with
You can also use a custom partition function hash such that hash(key) returns a hash value
To have finer control on partitionning, you must use the Scala API.
Questions
- Partitionning tweaking
- Shuffles monitoring
Thank you !
IFEBY030 – Technos Big Data – M1 MIDS/MFA/LOGOS – UParis Cité